
По виду этой оптики, идущей по лесу к коллектору, можно заключить, что монтажник немного не соблюдал технологию. Крепление на фото также подсказывает, что он, наверное, моряк – узел-то морской.
Я из команды обеспечения физической работоспособности сети, проще говоря – техподдержки, отвечающей за то, чтобы лампочки на роутерах мигали, как надо. У нас «под крылом» разные крупные компании с инфраструктурой по всей стране. Внутрь их бизнеса не лезем, наша задача – чтобы работала сеть на физическом уровне и трафик проходил как надо.
Общий смысл работы – постоянный опрос узлов, снятие телеметрии, прогоны тестов (например, проверка настроек для поиска уязвимостей), обеспечение работоспособности, мониторинг приложений, трафика. Иногда инвентаризации и прочие извращения.
Расскажу про то, как это организовано и пару историй с выездов.
Наша команда сидит в офисе в Москве и снимает телеметрию сети. Собственно, это постоянные пинги узлов, а также получение данных мониторинга, если железки умные. Самая частая ситуация – пинг не проходит несколько раз подряд. В 80% случаев для розничной сети, например, это оказывается отключением электропитания, поэтому мы, видя такую картину, делаем следующее:
Диалоги иногда такие:
— Так, связь пропадает между зданиями №4 и 5. Проверь роутер в пятом.
— Порядок, включён. Коннекта нет.
— Ок, иди по кабелю до четвёртого корпуса, там ещё узел.
—… Оппа!
— Что случилось?
— Тут 4-й дом снесли.
— Что??
— Прикладываю фото в отчёт. Дом в SLA восстановить не смогу.

Но чаще всё же получается найти обрыв и восстановить канал.
Примерно 60% выездов – «в молоко», потому что либо перебито питание (лопатой, прорабом, злоумышленниками), либо провайдер не знает про свой сбой, либо же кратковременная проблема устраняется до прибытия монтажника. Однако бывают ситуации, когда мы узнаём о проблеме раньше пользователей и раньше ИТ-служб заказчика, и сообщаем о решении до того, как они вообще поймут, что что-то случилось. Чаще всего такие ситуации случаются ночью, когда активность в компаниях заказчиков низкая.
Как правило, у любой крупной компании есть свой IT-отдел, который чётко понимает специфику и задачи. В среднем и большом бизнесе работу «эникеев» и инженеров-сетевиков часто аутсорсят. Это просто выгодно и удобно. Например, один ритейлер имеет своих очень крутых айтишников, но занимаются они далеко не заменой роутеров и выслеживанием кабеля.
С мониторингом история часто заключается в том, что его нет. Или он был поднят 5 лет назад и не очень актуален. В самом простом случае, если мониторинга реально нет, предлагаем заказчику простой опенсорсный русский Zabbix бесплатно – и ему хорошо, и нам проще.
Первый способ — simple cheсks — это просто машина, которая пингует все узлы сети и следит за тем, чтобы они правильно отвечали. Такая реализация не требует вообще никаких изменений или минимальных косметических изменений в сети заказчика. Как правило, в очень простом случае мы ставим Заббикс прямо к себе в один из дата-центров. В более сложном, например, если используется своя защищённая сеть – на одну из машин в ЦОДе заказчика:
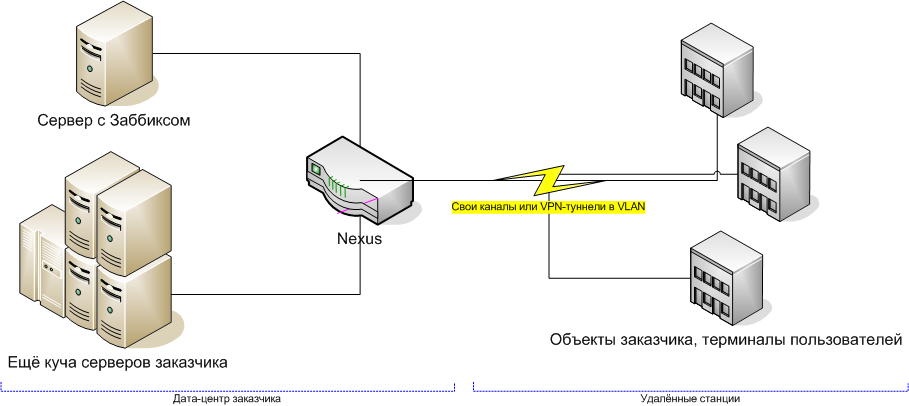
Заббикс можно применять и сложнее, например, у него есть агенты, которые ставятся на *nix и win-узлы и показывают системный мониторинг, а также режим external check (с поддержкой протокола SNMP). Тем не менее, если бизнесу нужно что-то подобное, то либо у них уже есть свой мониторинг, либо выбирается более функционально-богатый вариант решения. Конечно, это уже не открытое ПО, и это стоит денег, но даже банальная точная инвентаризация уже примерно на треть отбивает затраты.
Это мы тоже делаем, но это история коллег. Вот они прислали пару скринов Инфосима:


Я же оператор «аватара», поэтому расскажу дальше о своей работе.
Перед нами экраны с вот таким общим статусом:
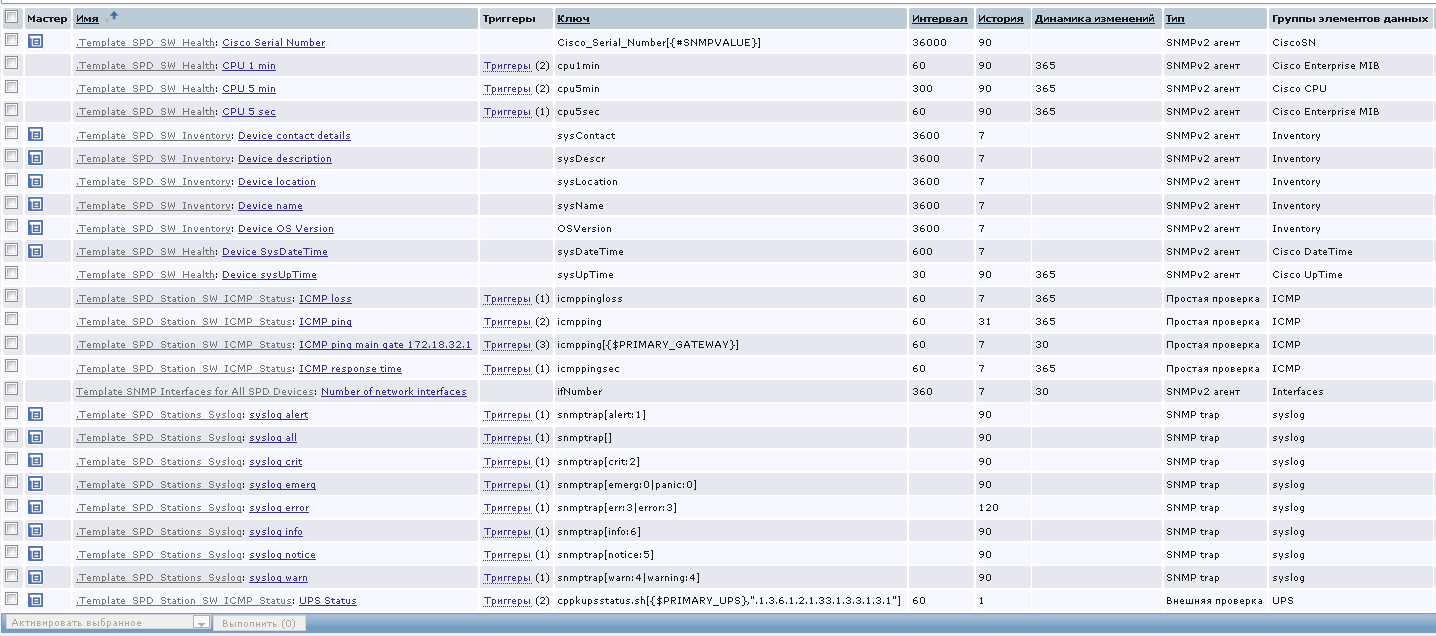
На этом объекте Zabbix собирает для нас довольно много информации: партийный номер, серийный номер, загрузка ЦПУ, описание устройства, доступность интерфейсов и т.п. Вся необходимая информация доступна из этого интерфейса.
Рядовой инцидент обычно начинается с того, что отваливается один из каналов, ведущих к, например, магазину заказчика (которых у него штук 200-300 по стране). Розница сейчас прошаренная, не то что лет семь назад, поэтому касса продолжит работу — каналов два.
Мы берёмся за телефоны и делаем минимум три звонка: провайдеру, электростанции и людям на месте («Да, мы тут арматуру грузили, чей-то кабель задели… А, ваш? Ну, хорошо, что нашли»).
Как правило, без мониторинга до эскалации прошли бы часы или дни — те же резервные каналы проверяют далеко не всегда. Мы знаем сразу и выезжаем сразу же. Если есть дополнительная информация кроме пингов (например, модель глючащей железки) – сразу комплектуем выездного инженера необходимыми частями. Дальше уже по месту.
Второй по частоте штатный вызов – выход из строя одного из терминалов у пользователей, например, DECT-телефона или Wi-Fi-роутера, раздававшего сеть на офис. Здесь мы узнаём о проблеме из мониторинга и почти сразу получаем звонок с деталями. Иногда звонок ничего нового не добавляет («Трубку беру, не звонит чего-то»), иногда очень полезен («Мы его со стола уронили»). Понятно, что во втором случае это явно не обрыв магистрали.
Оборудование в Москве берётся с наших складов горячего резерва, у нас их несколько типа таких:

У заказчиков обычно есть свои запасы часто выходящих из строя комплектующих – трубок для офиса, блоков питания, вентиляторов и так далее. Если же нужно доставить что-то, чего нет на месте, не в Москву, обычно мы едем сами (потому что монтаж). Например, у меня был ночной выезд в Нижний Тагил.
Если у заказчика есть свой мониторинг, они могут выгружать данные нам. Иногда мы разворачиваем Заббикс в режиме опроса, просто чтобы обеспечить прозрачность и контроль SLA (это тоже бесплатно для заказчика). Дополнительные датчики мы не ставим (это делают коллеги, которые обеспечивают непрерывность производственных процессов), но можем подключиться и к ним, если протоколы не экзотические.
В целом – инфраструктуру заказчика не трогаем, просто поддерживаем в том виде, как она есть.
По опыту скажу, что последние десять заказчиков перешли на внешнюю поддержку из-за того, что мы очень предсказуемые в плане затрат. Чёткое бюджетирование, хорошее управление кейсами, отчёт по каждой заявке, SLA, отчёты по оборудованию, профилактика. В идеале, конечно, мы для CIO заказчика типа уборщиц — приходим и делаем, всё чисто, не отвлекаем.
Ещё из того, что стоит отметить – в некоторых крупных компаниях настоящей проблемой становится инвентаризация, и нас иногда привлекают чисто для её проведения. Плюс мы же делаем хранение конфигураций и их менеджмент, что удобно при разных переездах-переподключениях. Но, опять же в сложных случаях это тоже не я – у нас есть специальная команда, которая перевозит дата-центры.
И ещё один важный момент: наш отдел не занимается критичной инфраструктурой. Всё внутри ЦОДов и всё банковско-страховое-операторское, плюс системы ядра розницы — это икс-команда. Вот эти ребята.
Многие современные устройства умеют отдавать много сервисной информации. Например, у сетевых принтеров очень легко мониторится уровень тонера в картридже. Можно заранее рассчитывать на срок замены, плюс иметь уведомление на 5-10% (если офис вдруг начал бешено печатать не в стандартном графике) — и сразу отправлять эникея до того, как у бухгалтерии начнётся паника.
Очень часто у нас забирают годовую статистику, которую делает та же система мониторинга плюс мы. В случае с Заббиксом это простое планирование затрат и понимание, что куда делось, а в случае с Инфосимом – ещё и материал для расчёта масштабирования на год, загрузки админов и всякие другие штуки. В статистике есть энергопотребление – в последний год почти все стали его спрашивать, видимо, чтобы раскидывать внутренние затраты между отделами.
Иногда получаются настоящие героические спасения. Такие ситуации – большая редкость, но из того, что помню за этот год – увидели около 3 ночи повышение температуры до 55 градусов на цискокоммутаторе. В далёкой серверной стояли «глупые» кондиционеры без мониторинга, и они вышли из строя. Мы сразу вызвали инженера по охлаждению (не нашего) и позвонили дежурному админу заказчика. Он потушил часть некритичных сервисов и удержал серверную от thermal shotdown до приезда парня с мобильным кондиционером, а потом и починки штатных.
У Поликомов и другого дорогого оборудования видеоконференцсвязи очень хорошо мониторится степень зарядки батарейки перед конференциями, тоже важно.
Мониторинг и диагностика нужны всем. Как правило, самим без опыта внедрять долго и сложно: системы бывают либо предельно простые и преднастроенные, либо с авианосец размером и с кучей типовых отчётов. Заточка напильником под компанию, придумывание реализации своих задач внутреннего ИТ-подразделения и вывод информации, которая им нужна больше всего, плюс поддержка всей истории в актуальном состоянии – путь грабель, если нет опыта внедрений. Работая с системами мониторинга, мы выбираем золотую середину между бесплатными и топовыми решениями – как правило, не самых популярных и «толстых» вендоров, но чётко решающих задачу.
Один раз было достаточно нетипичное обращение. Заказчику нужно было отдать роутер какому-то своему обособленному подразделению, причём точно по описи. В роутере был модуль с указанным серийником. Когда роутер начали готовить в дорогу, выяснилось, что этого модуля что-то нет. И найти его никто не может. Проблему слегка усугубляет тот факт, что инженер, который в прошлом году работал с этим филиалом, уже на пенсии, и уехал ко внукам в другой город. Связались с нами, попросили поискать. К счастью, железо давало отчёты по серийникам, а Инфосим делал инвентаризацию, поэтому мы за пару минут нашли этот модуль в инфраструктуре, описали топологию. Беглеца выследили по кабелю – он был в другой серверной в шкафу. История перемещения показала, что попал он туда после выхода из строя аналогичного модуля.

Много инцидентов с камерами. Однажды вышло из строя сразу 3 камеры. Обрыв кабеля на одном из участков. Монтажник задул новый в гофру, две камеры из трёх после ряда шаманств поднялись. А третья – нет. Более того, непонятно, где она вообще. Поднимаю видеопоток – последние кадры прямо перед падением – 4 утра, подходит трое мужиков в шарфах на лицах, что-то яркое внизу, камера сильно трясётся, падает.
Один раз настраивали камеру, которая должна фокусироваться на «зайцах», лазящих через забор. Пока ехали, думали, как будем обозначать точку, где должен появляться нарушитель. Не пригодилось – за те 15 минут, что мы там были, на объект проникло человек 30 только в нужной нам точке. Прямо настроечная таблица.
Как я уже приводил пример выше, история про снесённое здание – не анекдот. Один раз пропал линк до оборудования. На месте – нет павильона, где проходила медь. Павильон снесли, кабель пропал. Мы увидели, что маршрутизатор сдох. Монтажник приехал, начинает смотреть – а расстояние там между узлами пара километров. У него в наборе випнетовский тестер, стандарт — прозвонил от одного коннектора, прозвонил от другого – пошёл искать. Обычно проблему сразу видно.
 Выслеживание кабеля: это оптика в гофре, продолжение истории с самого верха поста про морской узел. Здесь в итоге кроме совершенно удивительного монтажа обнаружилась проблема в том, что кабель отошёл от креплений. Тут лазят все, кому не лень, и расшатывают металлоконструкции. Примерно пятитысячный представитель пролетариата порвал оптику.
Выслеживание кабеля: это оптика в гофре, продолжение истории с самого верха поста про морской узел. Здесь в итоге кроме совершенно удивительного монтажа обнаружилась проблема в том, что кабель отошёл от креплений. Тут лазят все, кому не лень, и расшатывают металлоконструкции. Примерно пятитысячный представитель пролетариата порвал оптику.
На одном объекте примерно раз в неделю отключались все узлы. Причём в одно и то же время. Мы довольно долго искали закономерность. Монтажник обнаружил следующее:
На одном объекте в одно и то же время ночью выключалось оборудование. Выяснилось, что местные умельцы подключились к нашему питанию, вывели удлинитель и втыкают туда чайник и электроплитку. Когда эти устройства работают одновременно – выбивает весь павильон.
В одном из магазинов нашей необъятной родины постоянно с закрытием смены падала вся сеть. Монтажник увидел, что всё питание выведено на линию освещения. Как только в магазине отключают верхнее освещение зала (потребляющее очень много энергии), отключается и всё сетевое оборудование.
Был случай, что дворник лопатой перебил кабель.
Часто видим просто медь, лежащую с сорванной гофрой. Один раз между двумя цехами местные умельцы просто пробросили витую пару без всякой защиты.
Подальше от цивилизации сотрудники часто жалуются что их облучает «наше» оборудование. Коммутаторы на каких-нибудь далёких объектах могут быть в той же комнате, что и дежурный. Соответственно, нам пару раз попадались вредные бабки, которые всеми правдами и неправдами отключали их в начале смены.
Ещё в одном далёком городе на оптику вешали швабру. Отколупали гофру от стены, стали использовать её как крепёж для оборудования.

В данном случае с питанием явно есть проблемы.
Я из команды обеспечения физической работоспособности сети, проще говоря – техподдержки, отвечающей за то, чтобы лампочки на роутерах мигали, как надо. У нас «под крылом» разные крупные компании с инфраструктурой по всей стране. Внутрь их бизнеса не лезем, наша задача – чтобы работала сеть на физическом уровне и трафик проходил как надо.
Общий смысл работы – постоянный опрос узлов, снятие телеметрии, прогоны тестов (например, проверка настроек для поиска уязвимостей), обеспечение работоспособности, мониторинг приложений, трафика. Иногда инвентаризации и прочие извращения.
Расскажу про то, как это организовано и пару историй с выездов.
Как это обычно бывает
Наша команда сидит в офисе в Москве и снимает телеметрию сети. Собственно, это постоянные пинги узлов, а также получение данных мониторинга, если железки умные. Самая частая ситуация – пинг не проходит несколько раз подряд. В 80% случаев для розничной сети, например, это оказывается отключением электропитания, поэтому мы, видя такую картину, делаем следующее:
- Сначала звоним провайдеру по поводу аварий
- Потом – на электростанцию по поводу отключения
- Затем пытаемся установить связь с кем-нибудь на объекте (это не всегда удаётся, например, в 2 ночи)
- И, наконец, если за 5-10 минут вышеописанное не помогло, выезжаем сами или отправляем «аватара» — инженера-контрактника, сидящего где-нибудь в Ижевске или Владивостоке, если проблема там.
- С «аватаром» держим постоянную связь и «ведём» его по инфраструктуре — у нас датчики и сервис-мануалы, у него— плоскогубцы.
- Потом инженер присылает нам отчёт с фото по поводу того, что же это было.
Диалоги иногда такие:
— Так, связь пропадает между зданиями №4 и 5. Проверь роутер в пятом.
— Порядок, включён. Коннекта нет.
— Ок, иди по кабелю до четвёртого корпуса, там ещё узел.
—… Оппа!
— Что случилось?
— Тут 4-й дом снесли.
— Что??
— Прикладываю фото в отчёт. Дом в SLA восстановить не смогу.
Но чаще всё же получается найти обрыв и восстановить канал.
Примерно 60% выездов – «в молоко», потому что либо перебито питание (лопатой, прорабом, злоумышленниками), либо провайдер не знает про свой сбой, либо же кратковременная проблема устраняется до прибытия монтажника. Однако бывают ситуации, когда мы узнаём о проблеме раньше пользователей и раньше ИТ-служб заказчика, и сообщаем о решении до того, как они вообще поймут, что что-то случилось. Чаще всего такие ситуации случаются ночью, когда активность в компаниях заказчиков низкая.
Кому это надо и зачем
Как правило, у любой крупной компании есть свой IT-отдел, который чётко понимает специфику и задачи. В среднем и большом бизнесе работу «эникеев» и инженеров-сетевиков часто аутсорсят. Это просто выгодно и удобно. Например, один ритейлер имеет своих очень крутых айтишников, но занимаются они далеко не заменой роутеров и выслеживанием кабеля.
Что мы делаем
- Работаем по обращениям — тикеты и панические звонки.
- Делаем профилактику.
- Следим за рекомендациями вендоров железа, например, по срокам ТО.
- Подключаемся к мониторингу заказчика и снимаем с него данные, чтобы выезжать по инцидентам.
С мониторингом история часто заключается в том, что его нет. Или он был поднят 5 лет назад и не очень актуален. В самом простом случае, если мониторинга реально нет, предлагаем заказчику простой опенсорсный русский Zabbix бесплатно – и ему хорошо, и нам проще.
Первый способ — simple cheсks — это просто машина, которая пингует все узлы сети и следит за тем, чтобы они правильно отвечали. Такая реализация не требует вообще никаких изменений или минимальных косметических изменений в сети заказчика. Как правило, в очень простом случае мы ставим Заббикс прямо к себе в один из дата-центров. В более сложном, например, если используется своя защищённая сеть – на одну из машин в ЦОДе заказчика:
Заббикс можно применять и сложнее, например, у него есть агенты, которые ставятся на *nix и win-узлы и показывают системный мониторинг, а также режим external check (с поддержкой протокола SNMP). Тем не менее, если бизнесу нужно что-то подобное, то либо у них уже есть свой мониторинг, либо выбирается более функционально-богатый вариант решения. Конечно, это уже не открытое ПО, и это стоит денег, но даже банальная точная инвентаризация уже примерно на треть отбивает затраты.
Это мы тоже делаем, но это история коллег. Вот они прислали пару скринов Инфосима:
Я же оператор «аватара», поэтому расскажу дальше о своей работе.
Как выглядит типовой инцидент
Перед нами экраны с вот таким общим статусом:
На этом объекте Zabbix собирает для нас довольно много информации: партийный номер, серийный номер, загрузка ЦПУ, описание устройства, доступность интерфейсов и т.п. Вся необходимая информация доступна из этого интерфейса.
Рядовой инцидент обычно начинается с того, что отваливается один из каналов, ведущих к, например, магазину заказчика (которых у него штук 200-300 по стране). Розница сейчас прошаренная, не то что лет семь назад, поэтому касса продолжит работу — каналов два.
Мы берёмся за телефоны и делаем минимум три звонка: провайдеру, электростанции и людям на месте («Да, мы тут арматуру грузили, чей-то кабель задели… А, ваш? Ну, хорошо, что нашли»).
Как правило, без мониторинга до эскалации прошли бы часы или дни — те же резервные каналы проверяют далеко не всегда. Мы знаем сразу и выезжаем сразу же. Если есть дополнительная информация кроме пингов (например, модель глючащей железки) – сразу комплектуем выездного инженера необходимыми частями. Дальше уже по месту.
Второй по частоте штатный вызов – выход из строя одного из терминалов у пользователей, например, DECT-телефона или Wi-Fi-роутера, раздававшего сеть на офис. Здесь мы узнаём о проблеме из мониторинга и почти сразу получаем звонок с деталями. Иногда звонок ничего нового не добавляет («Трубку беру, не звонит чего-то»), иногда очень полезен («Мы его со стола уронили»). Понятно, что во втором случае это явно не обрыв магистрали.
Оборудование в Москве берётся с наших складов горячего резерва, у нас их несколько типа таких:
У заказчиков обычно есть свои запасы часто выходящих из строя комплектующих – трубок для офиса, блоков питания, вентиляторов и так далее. Если же нужно доставить что-то, чего нет на месте, не в Москву, обычно мы едем сами (потому что монтаж). Например, у меня был ночной выезд в Нижний Тагил.
Если у заказчика есть свой мониторинг, они могут выгружать данные нам. Иногда мы разворачиваем Заббикс в режиме опроса, просто чтобы обеспечить прозрачность и контроль SLA (это тоже бесплатно для заказчика). Дополнительные датчики мы не ставим (это делают коллеги, которые обеспечивают непрерывность производственных процессов), но можем подключиться и к ним, если протоколы не экзотические.
В целом – инфраструктуру заказчика не трогаем, просто поддерживаем в том виде, как она есть.
По опыту скажу, что последние десять заказчиков перешли на внешнюю поддержку из-за того, что мы очень предсказуемые в плане затрат. Чёткое бюджетирование, хорошее управление кейсами, отчёт по каждой заявке, SLA, отчёты по оборудованию, профилактика. В идеале, конечно, мы для CIO заказчика типа уборщиц — приходим и делаем, всё чисто, не отвлекаем.
Ещё из того, что стоит отметить – в некоторых крупных компаниях настоящей проблемой становится инвентаризация, и нас иногда привлекают чисто для её проведения. Плюс мы же делаем хранение конфигураций и их менеджмент, что удобно при разных переездах-переподключениях. Но, опять же в сложных случаях это тоже не я – у нас есть специальная команда, которая перевозит дата-центры.
И ещё один важный момент: наш отдел не занимается критичной инфраструктурой. Всё внутри ЦОДов и всё банковско-страховое-операторское, плюс системы ядра розницы — это икс-команда. Вот эти ребята.
Ещё практика
Многие современные устройства умеют отдавать много сервисной информации. Например, у сетевых принтеров очень легко мониторится уровень тонера в картридже. Можно заранее рассчитывать на срок замены, плюс иметь уведомление на 5-10% (если офис вдруг начал бешено печатать не в стандартном графике) — и сразу отправлять эникея до того, как у бухгалтерии начнётся паника.
Очень часто у нас забирают годовую статистику, которую делает та же система мониторинга плюс мы. В случае с Заббиксом это простое планирование затрат и понимание, что куда делось, а в случае с Инфосимом – ещё и материал для расчёта масштабирования на год, загрузки админов и всякие другие штуки. В статистике есть энергопотребление – в последний год почти все стали его спрашивать, видимо, чтобы раскидывать внутренние затраты между отделами.
Иногда получаются настоящие героические спасения. Такие ситуации – большая редкость, но из того, что помню за этот год – увидели около 3 ночи повышение температуры до 55 градусов на цискокоммутаторе. В далёкой серверной стояли «глупые» кондиционеры без мониторинга, и они вышли из строя. Мы сразу вызвали инженера по охлаждению (не нашего) и позвонили дежурному админу заказчика. Он потушил часть некритичных сервисов и удержал серверную от thermal shotdown до приезда парня с мобильным кондиционером, а потом и починки штатных.
У Поликомов и другого дорогого оборудования видеоконференцсвязи очень хорошо мониторится степень зарядки батарейки перед конференциями, тоже важно.
Мониторинг и диагностика нужны всем. Как правило, самим без опыта внедрять долго и сложно: системы бывают либо предельно простые и преднастроенные, либо с авианосец размером и с кучей типовых отчётов. Заточка напильником под компанию, придумывание реализации своих задач внутреннего ИТ-подразделения и вывод информации, которая им нужна больше всего, плюс поддержка всей истории в актуальном состоянии – путь грабель, если нет опыта внедрений. Работая с системами мониторинга, мы выбираем золотую середину между бесплатными и топовыми решениями – как правило, не самых популярных и «толстых» вендоров, но чётко решающих задачу.
Один раз было достаточно нетипичное обращение. Заказчику нужно было отдать роутер какому-то своему обособленному подразделению, причём точно по описи. В роутере был модуль с указанным серийником. Когда роутер начали готовить в дорогу, выяснилось, что этого модуля что-то нет. И найти его никто не может. Проблему слегка усугубляет тот факт, что инженер, который в прошлом году работал с этим филиалом, уже на пенсии, и уехал ко внукам в другой город. Связались с нами, попросили поискать. К счастью, железо давало отчёты по серийникам, а Инфосим делал инвентаризацию, поэтому мы за пару минут нашли этот модуль в инфраструктуре, описали топологию. Беглеца выследили по кабелю – он был в другой серверной в шкафу. История перемещения показала, что попал он туда после выхода из строя аналогичного модуля.
Кадр из художественного фильма про Хоттабыча, точно описывающий отношение населения к камерам
Много инцидентов с камерами. Однажды вышло из строя сразу 3 камеры. Обрыв кабеля на одном из участков. Монтажник задул новый в гофру, две камеры из трёх после ряда шаманств поднялись. А третья – нет. Более того, непонятно, где она вообще. Поднимаю видеопоток – последние кадры прямо перед падением – 4 утра, подходит трое мужиков в шарфах на лицах, что-то яркое внизу, камера сильно трясётся, падает.
Один раз настраивали камеру, которая должна фокусироваться на «зайцах», лазящих через забор. Пока ехали, думали, как будем обозначать точку, где должен появляться нарушитель. Не пригодилось – за те 15 минут, что мы там были, на объект проникло человек 30 только в нужной нам точке. Прямо настроечная таблица.
Как я уже приводил пример выше, история про снесённое здание – не анекдот. Один раз пропал линк до оборудования. На месте – нет павильона, где проходила медь. Павильон снесли, кабель пропал. Мы увидели, что маршрутизатор сдох. Монтажник приехал, начинает смотреть – а расстояние там между узлами пара километров. У него в наборе випнетовский тестер, стандарт — прозвонил от одного коннектора, прозвонил от другого – пошёл искать. Обычно проблему сразу видно.
На одном объекте примерно раз в неделю отключались все узлы. Причём в одно и то же время. Мы довольно долго искали закономерность. Монтажник обнаружил следующее:
- Проблема происходит всегда в смену одного и того же человека.
- Отличается он от других тем, что носит очень тяжёлое пальто.
- За вешалкой для одежды смонтирован автомат.
- Крышку автомата кто-то унёс уже очень давно, ещё в доисторические времена.
- Когда этот товарищ приходит на объект, он вешает одежду, и она отключает автоматы.
- Он тут же включает их обратно.
На одном объекте в одно и то же время ночью выключалось оборудование. Выяснилось, что местные умельцы подключились к нашему питанию, вывели удлинитель и втыкают туда чайник и электроплитку. Когда эти устройства работают одновременно – выбивает весь павильон.
В одном из магазинов нашей необъятной родины постоянно с закрытием смены падала вся сеть. Монтажник увидел, что всё питание выведено на линию освещения. Как только в магазине отключают верхнее освещение зала (потребляющее очень много энергии), отключается и всё сетевое оборудование.
Был случай, что дворник лопатой перебил кабель.
Часто видим просто медь, лежащую с сорванной гофрой. Один раз между двумя цехами местные умельцы просто пробросили витую пару без всякой защиты.
Подальше от цивилизации сотрудники часто жалуются что их облучает «наше» оборудование. Коммутаторы на каких-нибудь далёких объектах могут быть в той же комнате, что и дежурный. Соответственно, нам пару раз попадались вредные бабки, которые всеми правдами и неправдами отключали их в начале смены.
Ещё в одном далёком городе на оптику вешали швабру. Отколупали гофру от стены, стали использовать её как крепёж для оборудования.
В данном случае с питанием явно есть проблемы.
Облачный мониторинг
Делали для одного глобального заказчика (компания непрерывного цикла производства с географией распределения от Европы по Сибири) облачный мониторинг по модели SaaS.Десятки объектов, в том числе – заводы и склады готовой продукции. Если у них падали каналы, а поддержка их осуществлялась из зарубежных офисов, то начинались задержки отгрузки, что по волне вело к убыткам дальше. Все работы делались по запросу и на расследование инцидента тратилось очень много времени.
Мы настроили мониторинг конкретно под них, потом допилили на ряде участков по особенностям именно их маршрутизации и железа. Сделали и сдали проект очень быстро.
Результат такой:
- За счет частичной передачи управления сетевой инфраструктурой удалось оптимизировать как минимум на 50%. Недоступность оборудования, загрузка канала, превышение рекомендованных производителем параметров: всё это фиксируется в течение 5-10 минут, диагностируется и устраняется в течение часа.
- При получении услуги из облака заказчик переводит капитальные расходы на развертывание своей системы сетевого мониторинга в операционные затраты на абонентскую плату за наш сервис, от которого в любой момент можно отказаться.
Преимущество облака в том, что в своем решении мы стоим как бы над их сетью и можем смотреть на все происходящее более объективно. В то время, если бы мы находились внури сети, мы видели бы картину только до узла отказа, и что за ним происходит, нам уже не было бы известно.
Пара картинок напоследок
Это — «утренний паззл»:

А это мы нашли клад:

В сундуке было вот что:

Ну и напоследок про самый весёлый выезд. Я как-то раз выезжал на объект розницы.
Там случилось следующее: сначала начало капать с крыши на фальшпотолок. Потом в фальшпотолке образовалось озеро, которое размыло и продавило одну из плиток. В результате всё это хлынуло на электрику. Дальше точно не знаю, что именно случилось, но где-то в соседнем помещении коротнуло, и начался пожар. Сначала сработали порошковые огнетушители, а потом приехали пожарные и залили всё пеной. Я приехал уже после них к разборку. Надо сказать, что циска 2960 врубилась после всего этого – я смог забрать конфиг и отправить устройство в ремонт.
Ещё один раз при сработке порошковой системы цисковский 3745 в одном банке был заполнен порошком почти полностью. Все интерфейсы были забиты – 2 по 48 портов. Надо было включать на месте. Вспомнили прошлый случай, решили попробовать снять конфиги «на горячую», вытрясли, почистили, как умели. Врубили – сначала устройство сказало «пфф» и чихнуло в нас большой струёй порошка. А потом заурчало и поднялось.
Источник: https://habrahabr.ru
Комментарии
Отправить комментарий